Subscribe to Blog via Email
Good Stats Bad Stats
Search Text
June 2026 S M T W T F S 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 -
Recent Posts
Good Stats Bad Stats
goodstatsbadstats.com
Uninformative Analysis – How useful is the Washington Metro?
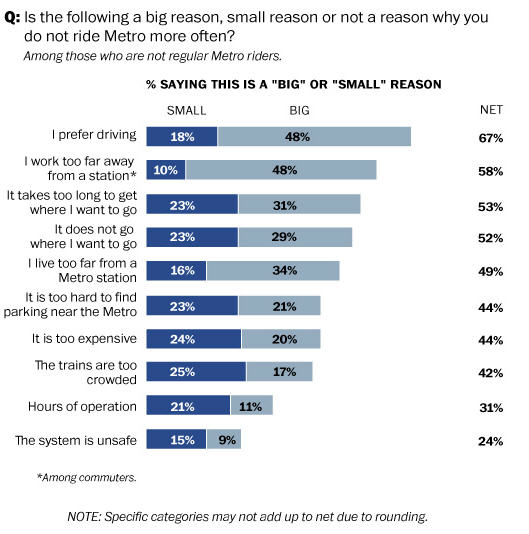 Combine a poorly designed question with a poor analysis and what to you get?
Combine a poorly designed question with a poor analysis and what to you get?
Last week the Washington Post conducted a survey on the Washington area Metro asking questions about attitudes and reasons for not using the system. A piece of the graphic they used to display the data is posted on the right. The article itself did not rely too heavily on the graphic.
Typically questions like “Is the following a….” are administered as a series of questions. The main question is repeated for each of the categories of interest to the survey designers. The order of the categories, as they are given to the respondents, is frequently randomized to avoid the inevitable biases the people have to focus on the earlier items in the list.
The problems here are many. The main issue is that it is very difficult to include all of the relevant important possible answered to the question. This question is directed towards those who are not frequent users of the Metro system. I fall into that group, yet my reason for not using the system is not among the list of reasons given. I generally do not go into downtown DC. That would be my main reason for not using the system. However when I do go into DC I prefer to use the Metro. I don’t have to deal with parking, traffic, and the over abundance of speed cameras that DC has installed. It is not that I am against the speed cameras, but with $100 plus fines and multiple cameras on the same road I don’t want to be caught having to watch the speedometer incessantly when I should be paying attention to traffic. I call that distracted driving.
A second problem is how to I respond the the later items once I have said that an item is a “big” issue for me. People approach that problem differently. Some think there should be a minimum of “big” issues. While others have no reservations about giving a long list of “big” issues. This makes the analysis of the answers to the question very complex. But also what is a “big” issue. Take the answer “I live too far from a Metro station.” There are people who take a 15 mile commuter bus ride, or drive 20 miles to the Metro station. A better but more complex description would be along the lines “it is too difficult to get to a Metro station.” But even that does not provide adequate data as the follow-up question would need to look at the reasons why it is too difficult.
Lastly the question is one that give a multidimensional answer set while the graphic provides a one dimensional view of the situation. The questions on the distance of the Metro station from my home and from my work site form a pair. Being too far from one of those place is a different situation than being too far from just one of them. Cross tabulations are important. Perhaps the Washington Post felt that such analysis was beyond the ability of their readers to understand.
This issue with the graphic reminds me of a homework problem my son was given when he was in 3ed grade. The problem started with a table. In the columns was a set of schools. The rows listed different items that were recycled – newspapers, aluminum, glass, etc. In each cell of the table was a count of the number of students in each school who recycled each item. The math problems for the students, based on the table, took the form “how many students recycled items at school A. Or how many students at school A recycled aluminum and glass. Unfortunately the answers were unknowable based on the data in the table as students were recycling multiple items at each school. This was obvious from the table as they provided a count of the number of students at each school and the sum of the counts of the number of students recycling the various items at the school was always greater than the number of students at the school. When I pointed out the problem to the teacher her response was she was just trying to teach the students how to add. I told her she was also teaching bad math at the same time. She was still using the same question in her classroom two years later.
When students are taught math and statistics like my son was in this case then years later the reporter makes the mistake of failing to understand when a one dimensional analysis does not explain what is going on in the multidimensional world.
Biomarkers and heart risk
I watched a news report last week that claimed that a relationship had been identified between heart risk and a set of three biomarkers. An abstract of the paper, titled, Aggregate Risk Score Based on Markers of Inflammation, Cell Stress, and Coagulation is an Independent Predictor of Adverse Cardiovascular Outcomes, is available. A description of the results is also available at the Emory University website as several of the coauthors are affiliated with the university.
Unfortunately the paper itself is hidden behind a pay wall at a cost of $31.50. I sent an e-mail to the contact for the paper last week requesting a copy of the paper and have not received a reply. I must say again my position is that while I understand the business model for published papers when the authors issue a press release and grant media interview to advertise their findings they then, in my opinion, assume the responsibility to provide their research to the public. Releasing their interpretation of the results while making it difficult or expensive for the public to review their work is unacceptable. Fortunately most authors who’s papers are hidden behind a pay wall will send a copy of their paper if requested to do so.
Even without the paper itself the results cited in the abstract and in the media raise several questions and concerns. Since I don’t have the paper many of these questions do not have readily available answers. They need to be addressed.
The researchers looked at 3,415 patients at who had been referred for cardiac catheterization based on suspected coronary artery disease. They then looked at three biomakers and determined a risk level based on the results of these makers.
Question 1: How were the biomakers identified? If they were selected based on a much larger set of biomarkers then was that taking into consideration in the analysis?
Question 2: How were the thresholds for each biomaarker determined. For example the used FDP ≥1.0 μg/ml. The actual threshold could have been any of several values. If the threshold used is a standard within the medial community that is one thing. But if the threshold is based on the data then that needed to be taken into consideration in the analysis.
Both of these first two questions are the equivalent of the well known multiple comparison issue in classical statistical analysis. Without consideration of the effect of making many possible comparisons then the consequence is over confidence in the results.
Question 3: Several additional biomarkers were available for each patient based on the reasons they were referred to the hospital for cardiac catheterization. Was this information used, useful or considered in the analysis. Was the results of the catherterization used in the analysis? What was the marginal additional value of the new test based on the three biomarkers after taking into consideration the reasons for the referral and the results obtained from the catheratization?
Question 4: What actions were taken based on the results of the catheratization? This test frequently leads to immediate heart bypass surgery. This alone certainly is an indicator of the risk of additional heart attacks. So this again raised the question of what is the marginal value of the new test using the three biomarkers.
These two questions raise the question of medial costs and the value of the test. Does the new test duplicate information already available? What is missing from the analysis is the more traditional treatment A vs treatment B evaluation. When proposing an medical treatment or the use of a new test this kind of analysis is critical. In the case of a new test the appropriate analysis may well be treatment A vs the combined treatment A and treatment B.
The abstract for the paper and the Emory website summary do not provide any of the customary information on possible conflict of interest on the part of the researchers. This information likely is in the paper itself. It is worth mentioning that two of the authors are affiliated with FirstMark. That information is readily avalibale when one looks at the author affiliations listed in the abstract. When I visited their website I found that FirstMark just now introducing at test that they refer to as “the first multiple biomarker test that accurately predicts near term (within 2-3 years) risk of myocardial infarction for suspected or confirmed coronary artery disease (CAD) patients.” I am not sure if this is the test referred to in the paper.
Posted in Telling the Full Story, The Media, Where's the Data?
Supermoon
The media has made a big deal this week about the “Supermoon.” CNN did a story and posted number of images. I have seen stories on the evening new on all of the networks.
I find the entire story a bit overblown.
The usual hype is that the moon is 11% or 14% bigger and 30% brighter. What the stories don’t say is what they are comparing to. As it turns out the ratios are the smallest the moon gets to the largest it gets as seen from the Earth. The 11% figure is based on averages while the 14% figure is based on the extremes over several centuries. The size of the full moon varies over a cycle with a length of about a year as the full moon occurs at various points in the moon’s orbit about the Earth.
Wikipedia does a fine job of explaining the orbital dynamics involved. But better than that a German site provides some of the relevant numbers to do a few useful calculation. I did a few of them and they gave me the results I expected.
On June 23, 2013 at the time of the full moon it was 356,991 kilometers from the Earth. On January 16, 2014 it will be 406,528 from the Earth. So this month is was almost 14% bigger than it will be next January when it will be at its smallest. Does that qualify it as a “Supermoon?”
Not so fast. The next full moon will be on July 22. At that time the moon will be 359,169 kilometers from the Earth. Guess what. It was less than 1% bigger this month and just over 1% brighter than it will be next month at the time of the full moon.
Somehow I don’t get the feeling I missed much by not making any effort to go out and see this media defined rare event.
Posted in The Media