Subscribe to Blog via Email
Good Stats Bad Stats
Search Text
June 2026 S M T W T F S 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 -
Recent Posts
Good Stats Bad Stats
goodstatsbadstats.com
Meaningless numbers on inheritance
Averages many times do not provide information. But when comparing the Untied States to the world by looking at only 15 counties I have to wonder what the authors of the piece posted at CNN titled “Average American inheritance: $177,000” with the byline “The United States is lagging behind other parts of the world when it comes to leaving inheritances for future generations.”
Click on the graphic and you will find that Europe is represented by only two counties, South America is represented by Brazil, Africa is not represented at all. In short the comparison is between a rather unrepresentative set of countries in the world.
Next, inheritance is a likely a very skewed distribution. The size of the skew likely determines the average. At least they could have used the median, or better yet in this case give me the quartiles.
The shortcomings in this piece are so obvious and pervasive that it provides virtually no meaningful data.
Metro fare comparsions – Graphics that don’t work
The Washington Post did a piece on Sunday discussing a potential fare increase for the Washington DC area Metro system. As part of that article they included a graphic comparing the costs of various subway systems across the country. The graphic fails on several key points.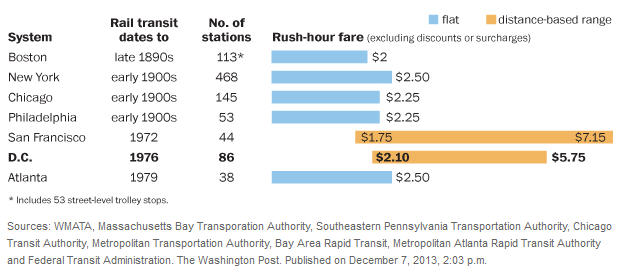
The presentation of the graphic is complicated because the Washington Metro system uses a fare structure that is based on both the distance traveled and the time of day of the trip. The same is true of the San Francisco Metro system. The other five metro systems shown in the graphic have a flat fare structure. The claim in the article is that those five systems were in place prior to the existence of the technology needed to implement a variable fare structure and that those living in the areas would not tolerate a move to a variable fare structure. The justification for a variable fare system usually takes on two points. First the users should pay for the length of the trip. And second, the flat fare structure discriminates against the poor who live in the inner cities.
This mix of fare structures makes the graphic meaningless in some ways. The Washington Metro and San Francisco fares look much worse than those in the other cities. Many readers will focus on the maximum fare for those two areas when making the comparisons. The graphic almost pushes the reader in that direction. More sophisticated readers may think in terms of the average of the high and low fares. For that Washington Metro system that would be $3.92. However this is not a good value to use. Those who read the details of the piece will find that as Metro calculates it; the total fare revenue divided by the number of fares collected, the average fare is about $2.90. That is still higher that the fare in the fixed rate systems but not anywhere near what the graphic implies.
Even the $2.90 figure is not a good number to use. In the graphic the Chicago system fare is cited as $2.25. However when I go to the Chicago Transit Authority webpage I find that $2.25 is the regular fare. There is also a reduced fare of $1.10 for some riders and a fare of $0.75 for students. There are also some who qualify for free rides. Thus I do not have an average fare for the Chicago system. I suspect the same if true for other systems. As a result the $2.25 figure for Chicago cannot be compared to the $2.90 figure for Washington.
But it gets more complicated. The federal government provides a generous subsidy to employees who use the metro and who agree not to use any federally subsidized parking and not be part of a carpool into work. The current subsidy is $245 a month. Even at the highest fare of $7.15 this would pay for 34 trips on the metro system. If this subsidy was paid directly to the Washington Metro the fares would likely be lower than they are now. We have a situation where the federal government subsidizes the metro system, yet that subsidy is not reflected in a reduced average fare. At the same time the local jurisdictions subsidize the system directly and this results in reduced fares. Thus the average fare is more a matter of how the system is subsidized than a measure of the direct impact on the users.
So later in the article when they writers point out
In a typical year, Metro collects about 67 cents in subway fares (give or take a few pennies) for every dollar it spends to operate the system. That “fare recovery ratio,” as transit experts call it, is among the highest in the country. The national average is a little less than 50 cents, according to the Federal Transit Administration.
The comparison is largely meaningless as the difference may well be more of a matter of how the system is subsidized – directly or indirectly – than is any measure of what some call the “fare recovery ratio.”
At this point the numbers in the graphic reflect this problem and the the accompanying article have become deceptive. Telling the full story in this situation is very difficult especially when key pieces of information are ignored.
The Marine Corps Marathon – cleaning the data
The 2014 Marine Corps Marathon took place on October 27th on a course that runs through Washington DC and Arlington, VA. This year my son ran in the race so I was there for the excitement. But being an observer introduced me to some to the data quality issues. During the race I was set up to get a text message as he passed the 10k, 20k, 30k, and 40k point in the race. The system failed miserably. I got the texts, but some were so late to be meaningless. After the race the more significant data quality issue become apparent as they had the wrong start time for him.
Now step back. The Marine Corps Marathon uses an RFI chip on each runner to track where they are in the race. It also is used to capture the individual runners start and finish times. With over 20,000 finishers in the race it is impossible for all to cross the start line at the same time. Also with 20,000 runners there are certain to be problems with the system. When one views the results page for the race there are two time markers for each runner – the net time and the clock time. The clock time is the actual time that the runner crossed the finish line. The net time is the time that it took the runner from the time he/she crossed the start line until the time they crossed the finish line. So, for example the first runner listed on the results page crossed the finish line in 3:53, but took 3:50 to run the race. For my son the net time was in error. He crossed the start line about three minutes into the race, but the initial results showed that he crossed at the gun. That is what got me looking at the data.
An attempt is made to put the faster runners at the front of the queue so that the faster runners do not have to pass the slower runners during the race. One of my hopes is to do some analysis on how well the predictions worked. But that is for a future post.
The results for the race were available on race day, but were labeled as unofficial. I downloaded those results and did a bit of analysis. The official results were posted about a week ago. So I download those result and looked again at some of the issues. At it turns out not all of the problems with the start time were resolved. It actually looks like very few were corrected.
The official results listed 23,468 finishers. It is not apparent until you look at the finish times that the list includes 88 runners who are in what are called the “rim” and “wheel” categories. Their results are also hidden on a separate page. I decided for my purposes to delete them from the list. One can argue if that is appropriate or not. This left 23,380 runners.
While downloading the data I discovered that at least one runner was in the file twice. A quick check of the file found two other cases. There were 23,377 runners remaining.
Next up was examination of the distribution of net time vs clock time for the runners. The first problem was that one runner, at least according to the data, started the race five minutes before the gun. Perhaps they were standing on the wrong side of the start line when the race started. You can watch the start of the race and the finish line videos here. The count of how many runners crossed the start line by seconds into the race was informative. It looks very much like the issue of getting the correct start time was not addressed for most runners. In the first second of the race 303 runners crossed the start line. In the next second this dropped to 54 runners. After that is quickly leveled off to 30-40 runners per second. Given the experience with my son I very much doubt that the 303 number is correct. Also looking at the run time of those who according to the database crossed the line in the first second I very much doubt that the count of 303 runners is anywhere near correct.
To put this in perspective the error rate is actually very low. Likely given the size of the crowd the RFI chip did not register when some of the runners crossed the start line. The system must have defaulted to placing them at the start line when the race started. This is a failure rate of around one percent. Runners who brought up the issues had their times corrected. My son’s was changed. I do not have any idea how they made the correction. For him they did ask him to provide any indication of where he was in the crowd. From the photos his friends took he was able to give them some bib numbers of other runners near him.
Next up, assuming I get to it is some analysis of the run time of those who ran the race and how well the placement of the runners in the queue worked.
Posted in Uncategorized